-
알고리즘 기초CS ( Computer Science )/알고리즘 2022. 10. 1. 16:55
정렬 알고리즘
- 알고리즘 문제 중 가장 기본 문제 중 하나
- 각 알고리즘 별 시간복잡도, 정렬 방법 숙지 필요
- 간단한 코드 작성 능력 필요
Worst case
(최악의 경우)Average
(평균)Bubble sort O(n^2) O(n^2) Selection sort O(n^2) O(n^2) Insertion sort O(n^2) O(n^2) Merge sort O(n log n) O(n log n) Quick sort O(n^2) O(n log n) - Selection Sort : O(n^2)
ㆍ매 loop 마다 다음을 수행
ㆍ최대 원소를 찾는다
ㆍ최소 원소와 맨 오른쪽 원소를 교환
ㆍ맨 오른쪽 원소를 제외
ㆍ1개의 원소만 남을 때까지 수행
selectionSort(A[], n) { for last <- n downto 2 { A[1,...,last] 중 가장 큰 수 A[k]를 찾는다; A[k] <-> A[last]; // A[k]와 A[last]의 값을 교환 } }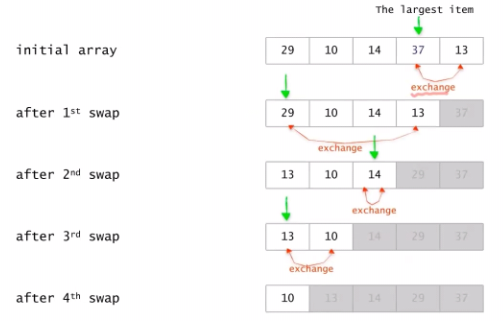
- Bubble Sort : O(n^2)
ㆍ가장 기본적인 sorting 알고리즘
ㆍ2개의 원소를 비교해서 자리를 변경할지 말지를 선택
ㆍ해당 작업을 모든 원소들에 대해 수행
bubbleSort(A[],n) { for last <- n downto 2 { for i <- to last-1 if(A[i] > A[i+1]) A[i] <-> A[i+1]; } }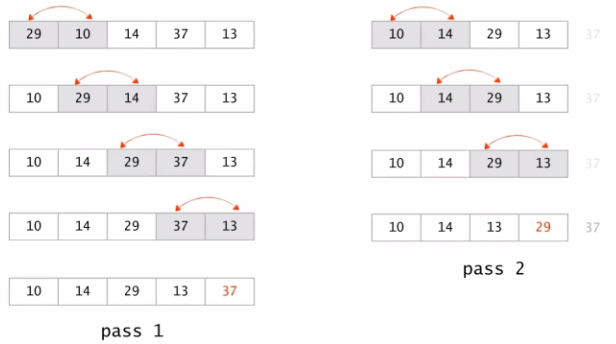
- Merge Sort : O(n log n)
ㆍQuick Sort 와 함께 Divide and Conquer 기법을 사용
ㆍ분할 → 정복 → 합병 순서로 알고리즘 구성
ㆍRecursion을 사용함 ( Recursive 알고리즘 )
ㆍQuick Sort와 Merge Sort 둘다 O(n log n)의 시간 복잡도인데 왜 Quick Sort가 일반적으로 더 빠를까?
ㆍLocality 개념
mergeSort(A[], left, right) { if(left < right) then { mid = (left + right) / 2; // p, q의 중간 지점 계산 mergeSort(A, left, mid); // 전반부 정렬 mergeSort(A, mid+1, right); // 후반부 정렬 merge(A, left, mid, right); // 합병 } } merge(A[], left, mid, right) { 정렬되어 있는 두 배열 A[left...mid]와 A[mid+1...right]을 합하여 정렬된 하나의 배열A[left...right]을 만든다. }
- Quick Sort : 평균 O(n log n) [최악 O(n^2)]
ㆍ핵심 키워드 : Pivot
ㆍPivot을 기준으로 작은 값과 큰 값을 구분해서 양쪽으로 나누어서 정렬
ㆍ예상 질문 리스트
ㆍPivot 관련 질문
1. 랜덤, 처음 값이나 마지막 값 등
2. Pivot 선택이 잘못될 경우?
ㆍQuick Sort 장단점
ㆍQuick Sort의 시간 복잡도가 최악의 경우 O(n^2)이 될 경우?
: Pivot을 잘못 선택해서 한쪽은 0개 나머지 반대는 n-1개가 계속해서 나뉘어질 경우

Hash Table
- Hash 함수란?
ㆍ해시 함수는 임의의 길이를 갖는 input을 입력받아 고정된 길이의 해시값을 출력하는 함수

- 특징
ㆍ1. 결과 값을 바탕으로 입력 값을 유추할 수 없음
ㆍ2. 눈사태 효과 : 입력값이 하나만 바뀌어도 결과 값이 완전 달라질 수 있다.
- Hash Table
ㆍ왜 Hash Table을 사용할까?
ㆍ예시 ) 도서관에 책이 어디 있는지 찾을 때
ㆍ 미정렬 > 정렬 > 정확한 위치
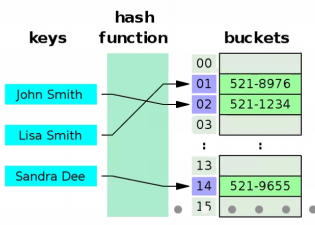
ㆍ특정 Key 값에 해당하는 데이터를 바로 찾을 수 있으므로 평균 시간 복잡도가 O(1)이 된다
ㆍ최악의 경우 O(n)이 되는데 Hash Collision과 관련이 있다
ㆍHash Collision ( 해시 충돌 )
ㆍ특정 key값을 변환하는 과정에서 서로 다른 key값이 같은 hash value로 변경되는 문제
ㆍ예를 들어 해시함수 h(x)가 7로 나눈 나머지 값이라 한다면?
ㆍ8개 이상의 값이 들어오면 무조건 같은 값이 1개 존재할 수 밖에 없다!
ㆍ해시 충돌과 관련해서 비둘기집의 원리까지 설명할 수 있다는 Best답변!
ㆍ비둘기집의 원리란?
: n+1개의 물건을 n개의 상자에 넣을 때 적어도 어느 한 상자에는 두 개 이상의 물건이 들어 있다는 원리를 말한다.
ㆍ해시 충돌이 최대한 적게 일어나게 만드는 해시 함수를 사용
ㆍ만약 모든 key값들에 대해서 해시 충돌이 일어날 경우 ( 최악의 해시 함수 사용 )
ㆍ시간 복잡도는 O(n)이 된다.
ㆍ다음 그림에서 한개의 인덱스에 n개의 데이터가 모두 들어가 있는 경우를 의미한다.
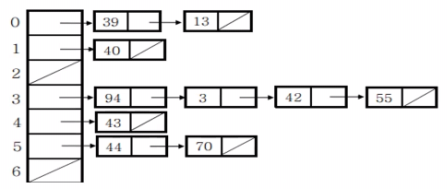
ㆍ이를 해결하기 위한 방법으로는 해시를 2차원으로 만들어서 2중 index를 관리하거나,
충돌이 일어나면 실제 주소값과 다른 주소에 value를 저장하는 방법 등이 있다!
ㆍCf. Open addressing과 Close addressing에 대해서 개념을 숙지하면 더 정확한 답변이 가능
ㆍ이렇게 좋으면 왜 모든 곳에 안쓸까?
ㆍ1. 공간 효율성이 떨어짐
ㆍ2. Hash Function 의존도가 높음
ㆍ3. 실제로 좋은 Hash Function은 그 자체 연산 시간도 소모된다.