-
데이터베이스 기초CS ( Computer Science )/데이터 베이스 2022. 10. 13. 14:05
- 현업에서 많이 사용하는 DB는
관계형 DB (RDB)와 비관계형 DB (NoSQL)로 나눌 수 있다.
관계형 DB
- 일반적으로 많이 알려진 Oracle, Mysql, Mssql 등이 존재
ㆍ이들 중 DB를 활용해본 경험이 있는지 물어보는 것이 기본 시작 질문
- 핵심 개념
ㆍ행(Row), 열(Column), 스키마(Schema)
ㆍ트랜잭션 (Transaction)
ㆍPK, FK, Index
ㆍ정규화
- 관계형 데이터베이스는 키(key)와 값(value)들의 간단한 관계를 테이블화 시킨 매우 간단한 원칙의 전산정보 데이터베이스이다.
- 왜 관계형?
ㆍ각각의 테이블들이 서로 관계를 맺을 수 있기 때문
ㆍTable : Row + Column + Schema
- 열 ( Column )
ㆍ항목의 속성(명칭)을 나타냄
ㆍ각각 정수, 텍스트 같은 데이터 유형을 지정
- 행 ( Row )
ㆍ각 데이터 항목을 저장한다.
- 스키마 ( Schema )
ㆍ필드는 데이터 유형 + 제약사항도 지정할 수 있는데 이러한 제약사항을 스키마라고 부른다.
ㆍ예를 들어 필드는 unique 또는 not null등의 제약사항을 지정할 수 있다.
- Table 예시

ㆍ위 테이블의 문제점이 있다면 무엇일까?
ㆍ어떻게 수정하면 좋을까?

ㆍ주문 테이블 관리자는 이제 고객 번호만 가지고 주문을 처리할 수 있게 되었음
ㆍ테이블을 분리하고 중복 데이터를 제거하는 과정을 ' 정규화 ' 라고 한다.
* 특정 테이블을 주고 정규화를 시켜보는 면접 문제 출제 가능.
제 1,2 정규화 등의 개념은 물어보진 않았음
- 정규화 목적
ㆍ불필요한 데이터를 제거, 중복을 최소화
ㆍ각종 이상 현상(Anomaly) 방지
- Join : 2개 이상의 테이블을 결합해서 한개의 테이블인 것처럼 출력
ㆍINNER JOIN : 조인하는 두 개의 테이블 모두에 데이터가 존재하는 행에 대해서만 출력
ㆍOUTER JOIN : 매칭되는 행이 없어도 결과를 가져오고 매칭되는 행이 없는 경우 NULL로 표시
- 인덱스 (Index)
ㆍDB를 검색 속도를 빠르게 도와주는 역할 ( Binary Tree 방식 )
ㆍ인덱스는 B-Tree 방식 ( binary, 이진법 ) 구조를 사용하는데 이진법으로 0과 1로만 탐색하기 때문에
속도가 빨라서 사용
ㆍ그래서 Select 문의 where, join 에서 좋은 성능을 발휘함
ㆍ대신 insert, update, delete문에서 성능이 떨어짐
* 1. Index를 쓰면 성능이 좋아진다고 했는데, 모든 컬럼에 인덱스를 사용하지 않을까?
* 2. 인덱스는 Binary Tree로 구현한다면 했는데, Hash Table을 사용하면 O(1)의 속도로 접근이 가능한데,
왜 그렇게 사용하지 않았을까?
- Transaction
ㆍ하나의 작업을 수행하기 위해 필요한 데이터베이스의 연산들을 모아놓은 것으로,
데이터베이스에서 논리적인 작업의 단위 ( commit / rollback 개념 숙지 )
ㆍ예시 ) 은행 ATM의 송금
- Transaction 4가지 특성 ( ACID )
ㆍ원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability)
- View 란?
ㆍ테이블에 대한 일부 데이터들을 따로 추출한 가상의 테이블
ㆍ실제 데이터가 저장되는 것은 아님
ㆍ따라서 View로 구성된 내용에 대해 Insert, Delete, Update에 제약이 있음
- SQL의 종류
ㆍDML ( Data Manipulation Language ) : Select, Insert, Update, Delete
ㆍDDL ( Data Definition Language ) : Create, Alter, Drop 등
ㆍDCL ( Data Control Language ) : Grant, Revoke
비관계형 DB ( NoSQL )
- 기본적으로 관계형 DB와 반대되는 접근 방식
- 스키마 없음
- 관계 없음
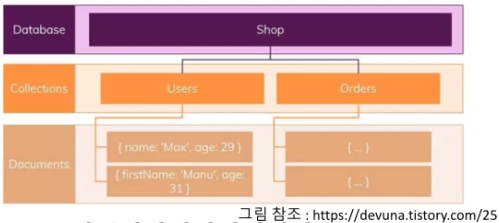
- 대표적으로 MongDB나 CouchDB 등이 있음
- Key, Value로 구성되어 있어서 json 형식과 비슷
- 대용량 데이터 처리에 효과적
- RDB에 비해서 Read, Write가 빠름
- 복잡한 데이터 구조를 표현하기 좋음
- 확장성이 좋음 ( 스키마가 없기 때문 )
- Cf. 위 예시는 Document Database의 특징, 요즘에는 Graph Database 개념도 등장
* 데이터 베이스는 개념과 내부 구현 원리도 파악하기