-
Apache Kafka for beginnerKafka 2023. 11. 27. 20:26
아파치 카프카 기초

- 카프카는 Source Application(클릭로그, 결제로그) 과 Taget Application(로그적제, 로그처리)의 커플링을 약하게 하기 위해 등장!
- Source Application의 데이터 포맷은 거의 제한이 없다. (json, csv etc..)

- 카프카는 위와 그림같이 아주 유연한 큐역할을 한다.
- 서버이슈 등에서도 데이터 손실없이 복구할 수 있다.
- 낮은 지연과 높은 처리량을 통해서 아주 효과적으로 데이터를 많이 처리할 수 있다.
토픽이란?
- 데이터가 들어갈 수 있는 공간
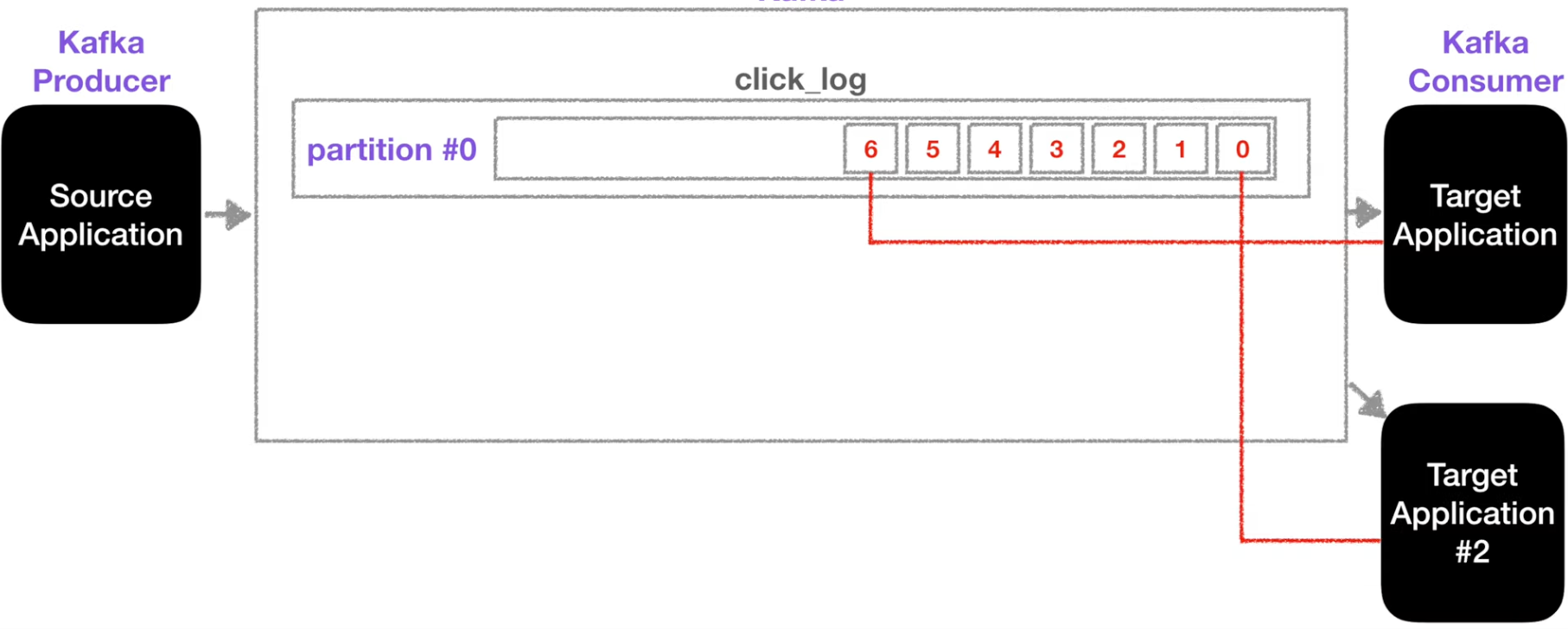
- 하나의 토픽은 여러개의 파티션을 구성될 수 있다.
ㆍConsumer는 오래된 파티션순으로 가져간다. (record들을 가져가도 데이터가 삭제되지는 않는다.)

1번 방식 (라운드 로빈) - 파티션이 2개이상이라면?!
ㆍ1) 키가 null이고, 기본 파티셔너 사용할 경우 -> 라운드 로빈(Round robin)으로 할당
ㆍ2) 키가 있고, 기본 파티셔너 사용할 경우 -> 키의 해시(hash) 값을 구하고, 특정 파티션을 할당
- 파티션은 늘릴 수는 있지만, 줄일 수는 없다!
ㆍ파티션을 늘리면 컨슈머의 개수를 늘려서 데이터 처리를 분산시킬 수 있다.
- 파티션의 데이터는 언제 삭제되는가?
ㆍ삭제되는 타이밍은 옵션의 따라 다르다.
ㆍlog.retention.ms : 최대 record 보존 시간
ㆍlog.retention.byte : 최대 record 보존 크기(byte)
브로커, 복제(replication), ISR(In-Sync-Replication)
- Kafka broker : 카프카가 설치되어 있는 서버 단위를 말한다.
ㆍ보통 3개 이상의 broker로 구성하여 사용하는 것은 권장한다.
- replication : partition의 복제를 뜻한다.
ㆍex) partition : 1, replication : 3 이면 원본 partition 1개와 복제 partition 2개가 존재한다.
ㆍ브로커의 개수에 따라서 replication개수가 제한된다. -> 브로커 개수가 3이면 replication은 4가 될 수 없다!
ㆍ원본 - Leader partition / 복제 - Follower partition
- ISR : Learder, Follower partition을 합친 뜻
- replication은 partition의 고가용성을 위해 사용된다.
ㆍ브로커 하나 죽어서 Leader partition이 죽는다면 Follower partition이 Leader의 역할을 승계한다.
- 프로듀서가 토픽의 파티션에 데이터를 전달할 때 전달받는 주체가 바로 Leader partition이다!
- 프로듀서의 ack 옵션
0 - 프로듀서는 Leader partition에 데이터를 전송하고 응답값은 받지않는다.
- 데이터 전송 및 복제 여부를 알 수 없다.
- 속도는 빠르지만 데이터 유실 가능성이 있다.1 - 프로듀서는 Leader partition에 데이터를 전송하고 응답값을 받는다.
- 나머지 partition의 복제 여부는 알 수 없다.
- 데이터를 받자마자 Leader partition에 장애가 난다면 데이터 유실 가능성이 있다.all - 1옵션의 추가로 Follower partition에 복제가 잘 이루어졌는지 응답값을 받는다.
- 데이터 유실은 없지만, 0과 1 옵션에 비해 확인하는 부분이 많기에 속도가 느리다.파티셔너(Partitioner) 란?

- 프로듀서가 데이터를 보내면 무조건 파티셔너를 통해서 브로커로 데이터가 전송
- 파티셔너는 데이터를 토픽에 어떤 파티션에 넣을지 결정하는 역할을 한다.
ㆍ레코드에 포함된 메시지 키 또는 메시지 값에 따라서 파티션의 위치가 결정된다.
- 파티셔너를 따로 설정하지 않는다면 UniformStickyPartitioner로 설정이 된다.
메시지 키가 있는 경우 메시지 키가 없는 경우 
- 해쉬값을 기준으로 어느 파티션으로 들어갈지 정해진다.
- 동일한 메시지 키를 가진 레코드는 동일한 해쉬값을 만들기 때문에 항상 동일한 파티션에 들어가는 것을 보장한다.
- 순서를 지켜서 데이터를 처리할 수 있다는 장점- 메시지 키가 없는 경우는 라운드 로빈으로 파티션에 들어간다.
- UniformStickyPartitioner 는프로듀서에서 배치로 모을 수 있는 최대한의 레코드들을 모아서 파티션으로 데이터 전송 -> 라운드 로빈 방식으로 저장- 파티셔너 인터페이스를 이용해서 커스텀 파티셔너 클래스를 만들면 메시지 키 또는 메시지 값 또는 토픽 이름에 따라서 어느 파티션에 데이터를 보낼것인지 정할 수 있다.
- ex) VIP 고객의 데이터를 좀 더 빨리 처리하고 싶다면? - 10개의 파티션이 있다면 커스텀 파티셔너를 만들어서 8개 파티션에는 VIP 고객의 데이터, 2개의 파티션에는 일반 회원의 데이터를 넣는다. 그렇다면 데이터 처리는 VIP 고객이 더 빠를 것이다.
컨슈머 랙(Consumer Lag) 이란?
- lag은 각 파티션의 오프셋기준으로 프로듀서가 넣은 데이터의 오프셋과 컨슈머가 가져가는 데이터의 오프셋의 차이를 기반으로 한다.
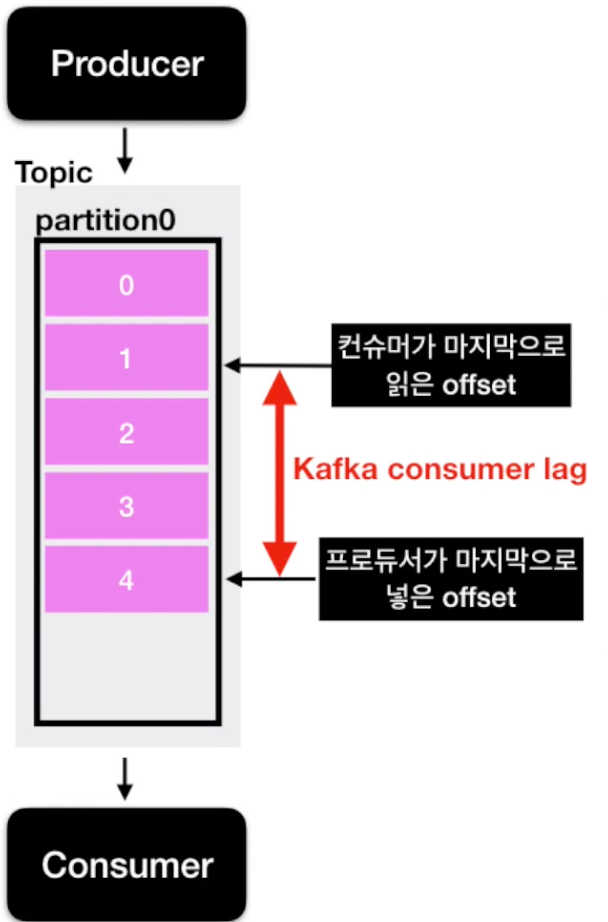
- 토픽에 여러 파티션이 존재하면 레그도 여러개가 존재
ㆍrecords-lag-max : 파티션의 레그 중 높은 숫자의 레그
- 이 lag 숫자를 통해 현재 해당 토픽에 대해 파이프 라인으로 연계되어 있는 프로듀서와 컨슈머에 대해 유추 가능
- 주로 컨슈머의 상태를 볼 때 사용
컨슈머 랙 모니터링 애플리케이션, 카프카 버로우(Burrow)
- Burrow는 컨슈머 lag 모니터링을 도와주는 독립적인 애플리케이션
- 특징
ㆍ1. 멀티 카프카 클러스터 지원
ㆍ2. Sliding Window를 통한 Consumer의 status 확인
- WARNING : 데이터양이 일시적으로 많아져 consumer offset이 증가되고 있다
- ERROR : 데이터 양이 많아지고 있는데 consumer가 데이터를 가져가지 않는다.
ㆍ3. HTTP API 제공
카프카, 레빗엠큐, 레디스 큐의 차이점
메시지 브로커 이벤트 브로커 - 메시지 브로커는 이벤트 브로커 역할을 할 수 없다
- 메시지를 받아서 적절히 처리하고 나면 즉시 또는 짧은 시간 내에 삭제되는 구조- 이벤트 브로커는 메시지 브로커의 역할을 할 수 있다.
- 첫번째는 이벤트 또는 메시지라고도 불리는 이 레코드를 하나만 보관하고 인덱스를 통해 개별 엑세스 관리
- 두번째는 업무상 필요한 시간 동안 이벤트를 보존할 수 있다.1. 딱 한번 일어난 이벤트 데이터를 브로커에 저장함으로서 단일 진실 공급원으로 사용 가능
2. 장애 발생 시 장애 발생시점부터 재처리 가능
3. 많은 양의 실시간 스트림 데이터를 효과적으로 처리레디스 큐, 레빗엠큐 카프카, AWS의 키네시스
아파치 카프카 개발
- 주키퍼 : 카프카 관련 정보를 저장하는 역할
- 카프카
카프카 프로듀서 애플리케이션
Producer role
- Topic에 해당하는 메시지를 생성
- 특정 Topic으로 데이터를 publish
- 처리 실패/재시도
* 카프카는 브로커 버전과 클라이언트 버전의 호환성 확인!
- 예제 코드
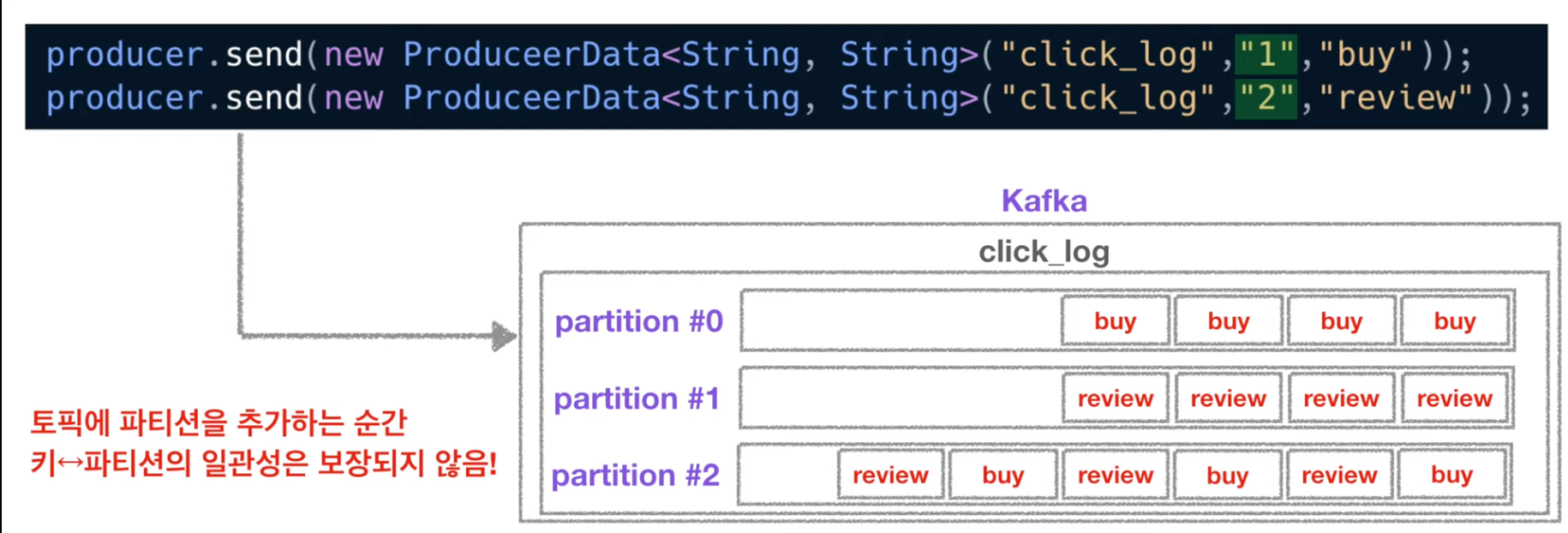
public class Producer { public static void main(String[] args) { Properties configs = new Properties(); configs.put("bootstrap.servers", "localhost:9092"); configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<String, String>(configs); ProducerRecord record = new ProducerRecord<String, String>("click_log", "login"); producer.send(record); producer.close; } }- 만약 키의 종류가 2개이고 파티션이 3개라면 key와 파티션의 매칭이 깨지기 때문에 key와 파티션 연결은 보장되지 않는다.
카프카 컨슈머 애플리케이션
- 폴링(polling) : 컨슈머가 데이터를 가져오는 것
Consumer role
- Topic의 partition으로부터 데이터 polling
- Partition offset 위치 기록(commit)
- Consumer group을 통해 병렬처리
- 예제 코드
public class Consumer { public static void main(String[] args) { Properties configs = new Properties(); configs.put("bootstrap.servers", "localhost:9092"); configs.put("group.id", "click_log_group"); configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs); consumer.subscribe(Arrays.asList("click_log")); // 폴링 루프 while(true) { ConsumerRecords<String, String> records = consumer.poll(500); //0.5초동안 데이터 도착을 기다림 for (ConsumerRecord<String, String> record : records) { System.out.println(record.value()); } } } }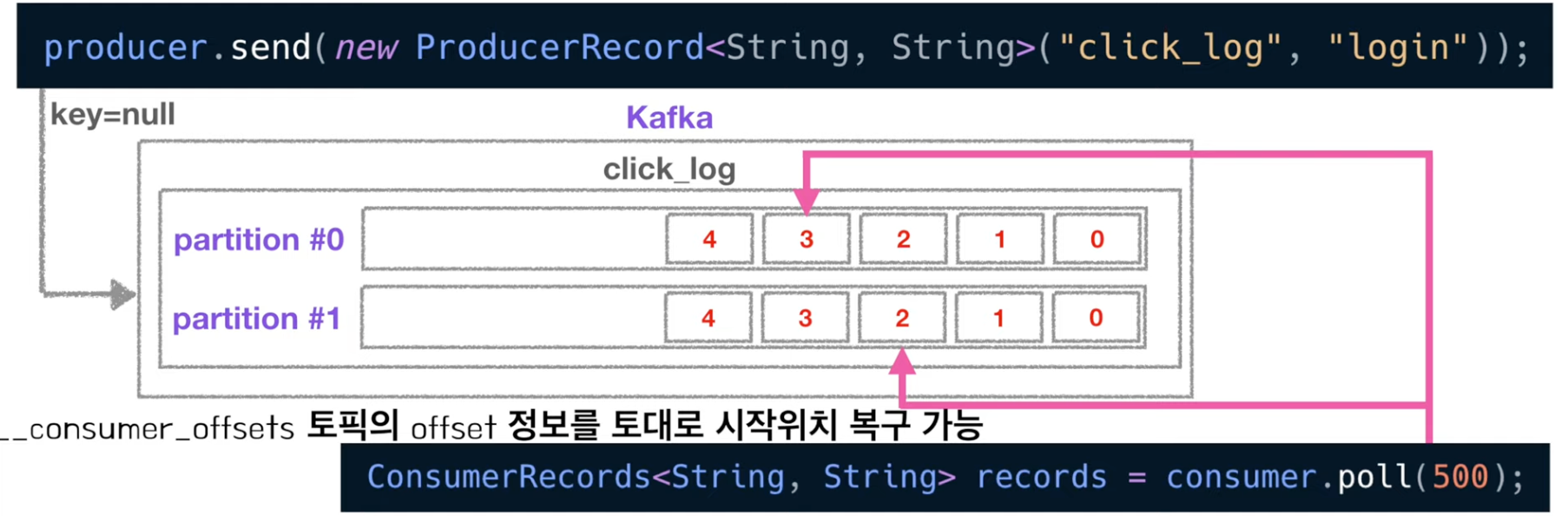
- consumer는 데이터를 읽기 시작하면 offset을 커밋하게 된다. - __consumer_offsets에 저장


- 컨슈머 그룹별로 토픽별로 offset을 나누어 저장한다.
- 이러한 특징으로 하나의 토픽으로 들어온 데이터는 다양한 역할을 하는 여러 컨슈머들이 각자 원하는 데이터로 처리 가능