-
스프링 DB 데이터접근 원리 - 2. 커넥션풀과 데이터소스 이해Spring-Boot/스프링 DB 1편 - 데이터 접근 핵심 원리 2022. 6. 18. 13:07
커넥션 풀 이해
* 데이터베이스 커넥션을 매번 획득 *
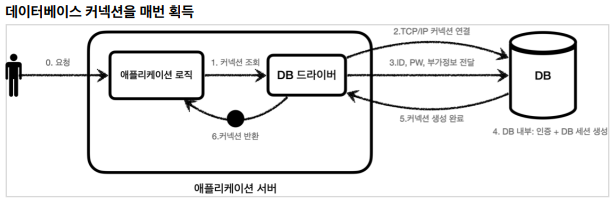
- 데이터베이스 커넥션을 획득할 떄는 다음과 같은 복잡한 과정을 거친다.
1. 애플리케이션 로직은 DB 드라이버를 통해 커넥션을 조회한다
2. DB드라이버는 DB와 TCP/IP 커넥션을 연결한다. 물론 이 과정에 3 way handshake 같은 TCP/IP 연결을 위한 네크워크 동작이 발생한다
3. DB드라이버는 TCP/IP 커넥션이 연결되면 ID,PW와 기타 부가정보를 DB에 전달한다
4. DB는 ID, PW를 통해 내부 인증을 완료하고, 내부에 DB세션을 생성ㅎ나다
5. DB는 커넥션 생성이 완료되었다는 응답을 보낸다
6. DB 드라이버는 커넥션 객체를 생성해서 클라이언트에 반환한다.
- 이렇게 커넥션을 새로 만드는 것은 과정도 복잡하고 시간도 많이 많이 소모되는 일이다
- DB는 물론이고 애플리케이션 서버에서도 TCP/IP 커넥션을 새로 생성하기 위한 리소스를 매번 사용해야한다.
- 애플리케이션을 사용할 때, SQL을 실행하는 시간 뿐만 아니라 커넥션을 새로 만드는 시간이 추가되기 때문에 결과적으로 응답속도에 영향을 준다
* 참고 *
- 데이터베이스마다 커넥션을 생성하는 시간은 다르다
- 시스템 상황마다 다르지만 MySQL 계열은 수 ms(밀리초) 정도로 매우 빨리 커넥션을 확보할 수 있다.
- 반면에 수십 밀리초 이상 걸리는 데이터베이스들도 있다.
- 이런 문제를 한번에 해결하는 아이디어가 바로 커넥션을 미리 생성해두고 사용하는 커넥션 풀이라는 방법이다
- 커넥션 풀은 이름 그대로 커넥션을 관리하는 풀이다.
* 커넥션 풀 초기화 *

- 애플리케이션 시작하는 시점에 커넥션 풀은 필요한 만큼 커넥션을 미리 확보해서 풀에 보관
* 커넥션 풀의 연결 상태 *
- 커넥션 풀에 들어 있는 커넥션은 TCP/IP로 DB와 커넥션이 연결되어 있는 상태이기 때문에 언제든지 즉시 SQL을 DB에 전달할 수 있다.
* 커넥션 풀 사용 *
- 애플리케이션 로직에서 이제는 DB 드라이버를 통해서 새로운 커넥션을 획득하는 것이 아니다
- 이제 커넥션 풀을 통해 이미 생성되어 있는 커넥션을 객체 참조로 그냥 가져다 쓰기만 하면 된다.
- 커넥션 풀에 커넥션을 요청하면 커넥션 풀은 자신이 가지고 있는 커넥션 중에 하나를 반환한다.
- 애플리케이션 로직은 커넥션 풀에서 받은 커넥션을 사용해서 SQL을 데이터베이스에 전달하고 그 결과를 받아서 처리한다
- 커넥션을 모두 사용하고 나면 이제는 커넥션을 종료하는 것이 아니라, 다음에 다시 사용할 수 있도록 해당 커넥션을 그대로 커넥션 풀에 반환하면 된다.
- 여기서 주의할 점은 커넥션을 종료하는 것이 아니라 커넥션이 살아있는 상태로 커넥션 풀에 반환해야 함
* 정리 *
- 적절한 커넥션 풀 숫자는 서비스의 특징과 애플리케이션 서버 스펙, DB 서버 스펙에 따라 다르기 때문에 성능 테스트를 통해서 정해야 한다
- 커넥션 풀은 서버당 최대 커넥션 수를 제한할 수 있다. 따라서 DB에 무한정 연결이 생성되는 것을 막아주어서 DB를 보호하는 효과도 있다
- 이런 커넥션 풀은 얻는 이점이 매우 크기 때문에 * 실무에서는 항상 기본으로 사용 * 한다
- 커넥션 풀은 개념적으로 단순해서 직접 구현할 수도 있지만, 사용도 편리하고 성능도 뛰어난 오픈소스 커넥션 풀이 많기 때문에 오픈소스를 사용하는 것이 좋다
- 대표적인 커넥션 풀 오픈 소스는 ' commons-dbcp2 ', ' tomcat-jdbc pool ', 'HikariCP' 등이 있다
- 성능과 사용의 편리함 측면에서 최근에는 ' hikariCP '를 주로 사용한다.
- 스프링 부트 2.0 부터는 기본 커넥션 풀로 ' hikariCP '를 제공한다
- 성능, 사용의 편리함, 안전성 측면에서 이미 검증이 되었기 때문에 커넥션 풀을 사용할 때는 고민할 것없이 ' hikariCP '를 사용하면 된다. 실무에서도 레거시 프로젝트가 아닌 이상 대부분 ' hikariCP '를 사용한다.
DataSource 이해
- 커넥션을 얻는 방법은 앞서 학습한 JDBC ' DriveManager '를 직접 사용하거나, 커넥션 풀을 사용하는 등 다양한 방법이 존재
* DriverManager를 통해 커넥션 획득하다가 커넥션 풀로 변경시 문제 *
- 예를 들어서 애플리케이션 로직에서 ' DriverManager '를 사용해서 커넥션을 획득하다가 ' HikariCP ' 같은 커넥션 풀을 사용하도록 변경하면 커넥션을 획득하는 애플리케이션 코드도 함께 변경해야 한다.
* 커넥션을 획득하는 방법을 추상화 *
- 자바에서 이런 문제를 해결하기 위해 ' javax.sql.DataSource '라는 인터페이스를 제공한다
- DataSource는 * 커넥션을 획득하는 방법을 추상화 * 하는 인터페이스이다
- 이 인터페이스의 핵심 기능은 커네션 조회 하나이다. ( 다른 일부 기능도 있지만 크게 중요하지 않다. )
* 정리 *
- 대부분의 커넥션 풀은 'DataSource' 인터페이스를 이미 구현해두었다.
- 따라서 개발자는 'DBCP 커넥션 풀', 'HikariCP 커넥션 풀'의 코드를 직접 의존하는 것이 아니라 'DataSource' 인터페이스에만 의존하도록 애플리케이션 로직을 작성하면된다.
- 커넥션 풀 구현 기술을 변경하고 싶으면 해당 구현체로 갈아끼우기만 하면 된다.
- 'DriverManager'는 'DataSource' 인터페이스를 사용하지 않는다
- 따라서 'DriverManager'는 직접 사용해야 한다.
- 따라서 'DriverManager' 를 사용하다가 'DataSource' 기반의 커넥션 풀을 사용하도록 변경하면 관련 코드를 다 고쳐야한다. 이런 문제를 해결하기 위해 스프링은 'DriverManager'도 'DataSource' 를 통해서 사용할 수 있도록 'DriverManagerDataSource' 라는 'DataSource'를 구현한 클래스를 제공
- 자바는 'DataSource' 를 통해 커넥션을 획득하는 방법을 추상화했다.
- 이제 애플리케이션 로직은 'DataSource' 인터페이스에만 의존하면된다.
* 파라미터 차이 *
기존 DriverManager 를 통해서 커넥션을 획득하는 방법과 DataSource를 통해서 커넥션을 획득하는 방법에는 큰 차이가 있다.
- DriverManager 는 커넥션을 획득할 때마다 'URL', 'USERNAME', 'PASSWORD' 같은 파라미터를 계속 전달해야한다.
- 반면에 DataSource를 사용하는 방식은 처름 객체를 생성할 때만 필요한 파라미터를 넘겨두고, 커넥션을 획득할 때는 단순히 ' dataSource.getConnection()' 만 호출하면 된다
* 설정과 사용의 분리 *
- * 설정 * : 'DataSource' 를 만들고 필요한 속성들을 사용해서 'URL', 'USERNAME', 'PASSWORD' 같은 부분을 입력하는 것을 말한다
ㆍ이렇게 설정과 관련된 속성들은 한 곳에 있는 것이 향후 변경에 더 유연하게 대처
- * 사용 * : 설정은 신경쓰지 않고, 'DataSource'의 'getConnection( )' 만 호출해서 사용하면 된다.
* 설정과 사용의 분리 설명 *
- 이 부분이 작아보이지만 큰 차이를 만들어내는데, 필요한 데이터를 'DataSource'가 만들어지는 시점에 미리 다 넣어두게 되면 'DataSource'를 사용하는 곳에서는 'dataSource.getConnection()' 만 호출하면 되므로, 'URL', 'USERNAME', 'PASSWORD' 같은 속성들에 의존하지 않아도 된다.
- 그냥 DataSource만 의존하고, 이런 속성을 몰라도 된다
- 쉽게 이야기해서 리포지토리( Repository )는 DataSource만 의존하고, 이런 속성을 몰라도 된다.
- 애플리케이션을 개발해보면 보통 설정은 한 곳에서 하지만, 사용은 수 많은 곳에서 하게 된다
- 덕분에 객체를 설정하는 부분과, 사용하는 부분을 좀 더 명확하게 분리할 수 있다.
* MyPool connection adder *
- 별도의 쓰레드를 사용해서 커넥션 풀에 커넥션을 채우고 있는 것을 확인할 수 있다
- 이 쓰레드는 커넥션 풀에 커넥션을 최대 풀 수까지 채운다
- 커넥션 풀에 커넥션을 채우는 것은 상대적으로 오래 걸리는 일
- 애플리케이션을 실행할 때 커넥션 풀을 채울 때 까지 마냥 대기하고 있다면 애플리케이션 실행 시간이 늦어진다.
- 따라서 이렇게 별도의 쓰레드를 사용해서 커넥션 풀을 채워야 애플리케이션 실행시간에 영향을 주지 않는다.
* DriverManagerDataSource 사용 *
- DriverManagerDataSource 를 사용하면 conn 0~5 번호를 통해서 항상 새로운 커넥션이 생성되어서 사용
* HikariDataSource 사용 *
- 커넥션 풀 사용시 conn0 커넥션이 재사용이 된 것을 확인할 수 있다
- 웹 애플리케이션에 동시에 여러 요청이 들어오면 여러 쓰레드에서 커넥션 풀의 커넥션을 다양하게 가져가는 상황을 확인 가능
* DI *
DriverManagerDataSource → HikariDataSource로 변경해도 MemberRepositoryV1의 코드는 전혀 변경하지 않아도 된다
이것이 DataSource를 사용하는 장점이다 ( DI + OCP )
'Spring-Boot > 스프링 DB 1편 - 데이터 접근 핵심 원리' 카테고리의 다른 글
스프링 DB 데이터접근 원리 - 6. 스프링과 문제해결-예외 처리, 반복 (0) 2022.08.29 스프링 DB 데이터접근 원리 - 5. 자바 예외 이해 (0) 2022.08.23 스프링 DB 데이터접근 원리 - 4. 스프링과 문제해결 - 트랜잭션 (0) 2022.06.22 스프링 DB 데이터접근 원리 - 3. 트랜잭션 이해 (0) 2022.06.19 스프링 DB 데이터접근 원리 - 1. JDBC 이해 (0) 2022.06.18